Toy프로젝트를 진행하며 웹사이트의 원하는 데이터를 가져와야 했습니다.
이번 포스팅은 Jsoup을 사용하며 웹페이지를 크롤링한 방법을 공유합니다.

Jsoup? Selenium?
Jsoup
- 정적인 자료를 수집하는 경우에 주로 사용합니다.
- 정적 데이터를 비교적 빠르게 수집할 수 있지만 브라우저가 아닌 HTTP Request를 사용하기 때문에 동적 데이터를 수집하기 위해서는 해당 서버의 인증키 요구 등 수집할 수 없는 경우가 많다.
- 또한 동적인 기능을 지원하지 않는 경우가 많다.
Selenium
- 빅데이터 관련, 동적인 자료를 수집할 때 주로 사용한다.
- Jsoup에 비해 속도는 느리지만 브라우저 드라이버를 사용하여 동적 데이터도 수집 가능하다.
[개인 의견]
아직 Selenium을 사용해보지 않은 초보 개발자의 입장에서 Selenium과 Jsoup의 차이점을 명확히 구분하고 설명드리기는 어렵습니다만(ㅜㅠ), 제가 느껴본 바를 그대로 설명해보겠습니다.
Selenium은 화면에 출력되는 모습 그대로(ex. 사용자가 보고있는 웹페이지)의 data를 크롤링할 때 유용할 것 같습니다. (macro를 구현한다던지..)
Jsoup은 화면에 뿌려지는 모습 보다는, 원시 코드(HTML 코드를 크롤링하여 활용)를 그대로 크롤링 하기에 유용한 것 같습니다.
Jsoup 사용해보기
Jsoup을 실제로 사용하기 전에 주요 요소 먼저 확인하겠습니다.
| 클래스명 | 설명 |
| Document | Jsoup 얻어온 결과 HTML 전체 문서 |
| Element | Document의 HTML 요소 |
| Elements | Element가 모인 자료형 |
| Connection | Jsoup의 connect 혹은 설정 메소드들을 이용해 만들어지는 객체(연결을 하기 위한 정보를 담고 있다) |
| Response | URL에 접속해 받은 결과(Document와 다르게 status 코드, status 메시지나 charset같은 헤더 메시지와 쿠키등을 가지고 있다) |
1. Dependencies 추가

+ maven일 경우 다음으로 dependency 추가 가능
compile group: 'org.jsoup', name: 'jsoup', version: '1.14.1'
2. 원하는 페이지 크롤링하기
(본 포스팅에서는 간단하게 웹페이지 크롤링으로 만족하기로~.~)
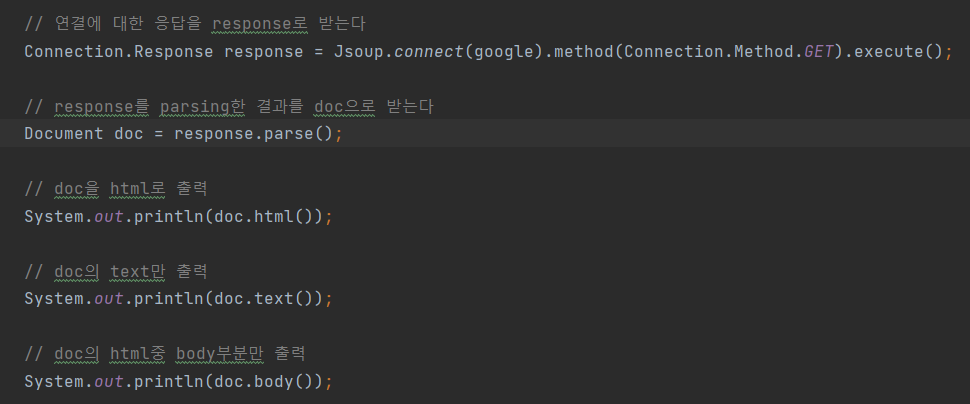
html(), text(), body()에 대한 각각의 결과 화면입니다.
# html()의 결과 화면
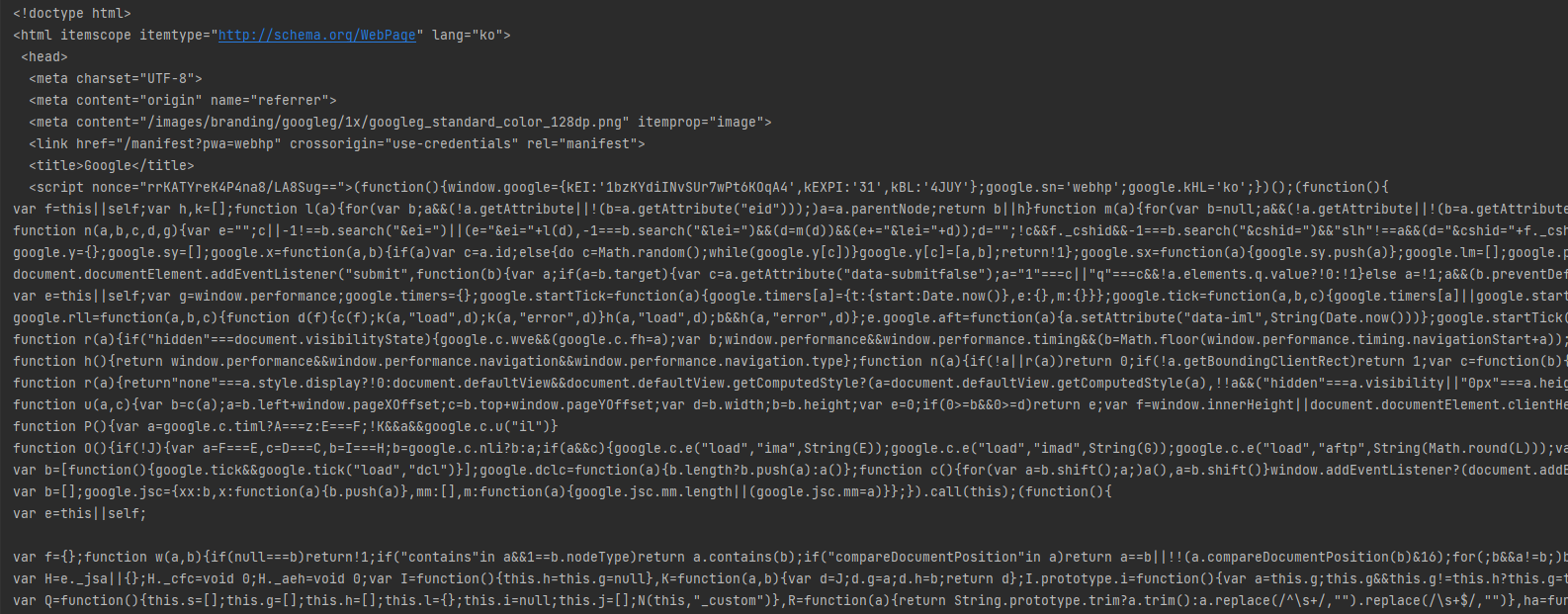
- 해당 웹페이지의 응답을 html로 출력한 모습입니다.
# text()의 결과 화면

- 웹페이지에서 텍스트에 해당하는 부분만 출력한 모습입니다.
# body()의 결과 화면

- html에서도 body의 내용만 출력한 모습입니다.
간단한 실습은 여기에서 종료하고 이후의 로그인이나 파일 업로드 등 활용은 다음 포스팅에서 진행하도록 하겠습니다.
감사합니다.

[출처] : https://partnerjun.tistory.com/42
Java HTML parser, Jsoup로 원하는 값 얻어내기 - 기본
Jsoup는 아주 강력하고 재미있는 라이브러리다. 단순한 HTML 문서 파싱을 넘어 웹 사이트에 대한 Request, Response를 모두 처리할 수 있다. 덕분에 일부 특별한 경우(플래시, 애플릿, ActiveX같은 비표준
partnerjun.tistory.com
[출처] : https://heekng.tistory.com/64
[Java] 크롤링 crawling, 셀레니움 Selenium
[Java] 크롤링 crawling, 셀레니움 Selenium 웹 크롤링의 정식 명칭은 Web Scraping이며, 웹 사이트에서 원하는 정보를 추출하는 것을 의미한다. 보통 웹 사이트는 HTML기반이기 때문에 정보를 추출할 페이
heekng.tistory.com
'Language > Java' 카테고리의 다른 글
| [Java] Jsoup (1) (0) | 2022.04.18 |
|---|---|
| [Java] JVM (1) (0) | 2022.02.08 |

