Dacon 풍력 발전량 예측 대회를 진행하였다.
지금껏 사용해 온 모델을 학습시킨 후 예측값을 추출한 후 제출하였는데 점수가 좋게 나오진 않았다.
성능 향상 방법을 구글링을 통해 찾아서 전처리를 여러 가지 방법으로 처리하여 진행을 해도 뛰어난 성능 향상을 느끼진 못했다.
그러다 예전에 Pycaret을 사용한 경험이 생각이 나서 AutoML에 대해 찾아보았다.
mljar-supervised라는 AutoML을 찾아 이 데이터에 적용해 보았다.
라이브러리 설치부터 제출까지 해보는 시간을 가져보자.
AutoML(mljar-supervised) 설치
pip install mljar-supervised위 명령어를 통해 AutoML 라이브러리를 설치할 수 있다.
데이터 설명
- train.csv
- 19275개의 데이터
- id : 샘플 별 고유 id
- temperature : 기온 (°C)
- pressure : 기압(hPa)
- humidity : 습도 (%)
- wind_speed : 풍속 (m/s)
- wind_direction : 풍향 (degree)
- precipitation : 1시간 강수량 (mm)
- snowing : 눈 오는 상태 여부 (False, True)
- cloudiness : 흐림 정도 (%)
- target : 풍력 발전량 (GW) (목표 예측값)
변수는 총 10개가 존재한다. 이 중 id 변수는 하나의 데이터의 고유 id로 모델 학습 시에 잘못된 학습을 할 수 있기 때문에 학습데이터에는 삭제하는 것이 좋다. target 변수는 목표 예측값이기 때문에 따로 y 값으로 저장하여 학습을 진행한다.
데이터 불러오기
import pandas as pd
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
submission = pd.read_csv('sample_submission.csv')
train.shape, test.shape, submission.shape데이터 살펴보기
train.head()
id 변수를 제외하고 9개의 변수 중 8개가 수치형 변수, 1개가 범주형 변수로 구성되어 있다.
train.describe()
수치형 변수의 통계량을 살펴보면,
- count - 총 19,275개의 데이터 모두 결측치없이 존재하는 것을 알 수 있다.
- mean - 각 변수의 평균값을 나타낸다.
- std - 각 변수의 편차
- min - 각 변수의 최소값
- 25% - 각 변수를 정렬했을 때, 25%에 해당하는 값
- 50% - 각 변수의 중앙값
- 75% - 각 변수의 75%에 해당하는 값
- max - 각 변수의 최댓값
EDA (탐색적 분석)
수치형 변수의 경우 히스토그램을 통해 전체적인 양상을 파악할 수 있다.
import matplotlib.pyplot as plt
train.hist(bins = 100, figsize = (18, 18))
plt.show()
train['snowing'].value_counts()

범주형 변수인 snowing 변수를 살펴봤을 때, False가 극단적으로 많은 비율을 차지하고 있다. 이런 변수는 삭제를 고려해 볼 수 있다. 여기서는 삭제하도록 하자.
데이터 전처리
EDA를 통해 수치형 변수를 확인해 보면, 정규분포 형태로 이루어져 있는 변수가 존재하는 반면에, 극단적으로 치우쳐져 있는 변수도 존재한다. 이러한 변수를 좀 더 효과적으로 예측하기 위해 전처리를 진행해야 한다.
X = train.drop(columns = ['id', 'snowing', 'target'], axis= 1)
test.drop(columns = ['id', 'snowing'], inplace = True)
y = train['target']
위에서 데이터를 살펴봤을 때, id 변수는 각 데이터의 고유번호를 나타내기 때문에 예측에서는 제외해야 한다고 했다.
스케일링을 진행하기 위해 목표 예측값을 따로 저장해 준다.
이후 스케일링을 진행한다.
from sklearn.preprocessing import StandardScaler
numeric_features = X.select_dtypes(exclude = 'object').columns
for col in numeric_features:
sc = StandardScaler()
X[col] = sc.fit_transform(X[[col]])
test[col] = sc.fit_transform(test[[col]])X.head()
AutoML 모델 학습
이제 모델을 학습시킬 준비는 모두 끝났다.
설치한 AutoML 라이브러리를 불러오자.
from supervised.automl import AutoML
import numpy as np
import random
import osautoml = AutoML(mode = 'Compete',
eval_metric = 'mae',
algorithms=['Extra Trees', 'LightGBM', 'CatBoost', 'Xgboost'],
random_state = 42)라이브러리를 불러오고, 정의를 해준다.
mode는 'Compete', 평가 지표는 이 대회에서 성적을 매기는 'mean_absolute_error'로 설정을 해주고, 모델은 Extra Trees, LightGBM, CatBoost, Xgboost로 지정해 주었다.
이제 모델을 학습해 보자.
automl.fit(X, y)시간이 꽤나 걸린다.
따로 검증데이터를 만들지 않아도 AutoML에서 자동으로 10-Fold CV를 통해 검증을 진행해 준다.
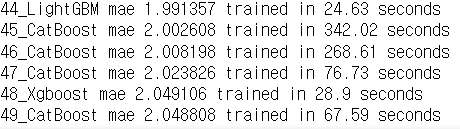
이런 식으로 모델을 학습 후 각 모델마다의 평가 지표를 보여준다.
예측
모델 학습이 끝나면 test 데이터셋에 대한 target 변수 값을 예측해 주자.
preds = automl.predict(test)예측한 값을 submission 데이터셋에 저장을 해주고 csv로 저장 후 데이콘에 제출하면 점수가 나온다.
submission['target'] = preds
submission.to_csv('automl.csv', index = False)
제출한 결과, 이전에 제출했던 점수보다 훨씬 높게 책정되었다.
성능을 더 올릴 수 있는 방법은 전처리에서 사용하는 스케일링, 변수 제거, 변수 생성 등 여러 가지 방법이 있을 수 있다.
'Language > Python' 카테고리의 다른 글
| [Python] PyPy3 vs Python3 (0) | 2023.01.14 |
|---|---|
| [Dacon] 해외 부동산 월세 예측 AI 경진대회 - 앙상블 (4) | 2023.01.05 |
| [FastAPI] PyCharm Community - setting (0) | 2022.12.26 |
| [Python] Input() vs sys.stdin.readline() 입력 함수 차이 (feat. python version) (0) | 2022.12.15 |
| [Python] 패키지(package)와 모듈(module) 알아보기 (0) | 2022.08.31 |


